Zig Threading Tutorial
Prequel
With the release of Zig 0.11.0, the language introduced channels
like in Go. However, in the same release, they announced that the support of
async functions is postponed (related
Github issue); they expect their support for the release 0.13.0.
Initially, I wanted to test channels, but:
0.11.0getsChannel, but unusable because it requires await functions0.10.0getsasync/awaitsupport with the option-fstage1, but theChannelis not part of the language
Finally, I switched to the solution of thread pools.
Introduction
In a previous post, I benchmarked Zig versus C with a naive prime-number algorithm. It used to be a single-threaded implementation; now, the goal is porting it into multi-threading.
The standard library of Zig has a type std.Thread that includes the basics of threading: spawn, join, Mutex… Also, it comes with
more advanced features, such as thread pools (they are not documented yet,
and this tutorial intends to be one proposition).
A thread pool consists of a group of (OS or green) threads waiting to execute tasks. Typically, a thread pool is designed to accept a variety of tasks that are not assigned to a specific thread, maximizing the parallelism. Here, one accounts for a single task defined as: testing whether an integer is prime or not.
I will detail two possible implementations:
- a manually spawned thread pool, where each thread is designed for a specific task;
- a managed-thread pool with
std.Thread.Pool, where threads accept any task.
The complete code is published on Github.
Thread-safe Structures
Allocator
Zig does not perform any hidden allocation, they should be all explicit. So, memory allocation is performed with the help of
an allocator std.mem.Allocator, it is similar to the C malloc, but it accepts more options: heap, fixed buffer, arena…
Beware, a basic std.mem.Allocator is not suitable for concurrency. So in the context of multi-threading and concurrent
memory allocations, the allocator must wrapped into a thread-safe allocator type as follows.
var single_threaded_arena = std.heap.ArenaAllocator.init(std.heap.page_allocator);
defer single_threaded_arena.deinit();
var thread_safe_arena: std.heap.ThreadSafeAllocator = .{
.child_allocator = single_threaded_arena.allocator(),
};
const arena = thread_safe_arena.allocator();
Queues
The standard library (stdlib) provides a type std.atomic.Queue(T: type). It allows multiple producers and readers performing
simultaneous operations with functions: put, get, remove… The queue items are structs of type Node with the required members:
pub const Node = struct {
.prev: ?*Node = null,
.next: ?*Node = null,
.data: T,
}
A ?-prefixed pointer is a so-called optional pointer,
which allows a null memory address (by default, a pointer in Zig is not nullable).
To deal with an optional pointer ?*T you must check whether it points to a memory location or not.
One of the options is within an if statement:
if (optional_ptr) |ptr| {
// acceded only if optional_ptr != null
// the pointer address is casted to `ptr`
} else {
// the optional_ptr = null
}
Or directly when accessing the value:
const val = optional_ptr.?.*;
Initialize and Fill Queues
Setting up a thread-safe queue is pretty easy. First, initialize it. Then, allocate nodes with the previously defined thread-safe allocator.
const U64Queue = std.atomic.Queue(u64);
var int_to_test = U64Queue.init();
const node: *Node = try arena.create(Node);
node.* = .{
.prev = undefined,
.next = undefined,
.data = value,
};
int_to_test.put(node);
As one can see, we set the values .prev and .next to undefined, they will be set the function put.
Get Nodes from Queue
One can safely access, from any thread, the Queue elements by calling get. It returns an optional node pointer ?*Node, set to null if the
queue is empty. Consequently, before playing the ?*Node value, test it:
if (int_to_test.get()) |node| {
const value = node.data;
// do sth. with the data
} else {
// empty queue
}
Thread Pool
A thread pool aims to maintain a group of always-running threads, in contrast with, a naïve implementation where one spawns and joins thread for every task. Such approach may, if the tasks are short, overload the OS-thread scheduler and waste CPU power for non-computational tasks.
Manual
First, we create a slice (and not an array because its size cannot be evaluated at compilation) of std.Thread.
var pool = try arena.alloc(std.Thread, cpu_count);
defer arena.free(pool);
for (pool) |*thread| {
thread.* = try std.Thread.spawn(.{}, isPrimeRoutine, .{ &int_to_test, &int_prime });
}
Each thread runs a function isPrimeRoutine. The function reads a queue of integers, tests the queued integers, sends the test result,
and finally returns when the queue is empty.
pub fn isPrimeRoutine(int_to_test: *U64Queue, int_prime: *U64Queue) void {
while (true) {
if (int_to_test.get()) |node| {
const value = node.data;
var is_value_prime = true;
var i: u64 = 2;
while (i < value) : (i += 1) {
if (value % i == 0) {
is_value_prime = false;
break;
}
}
if (is_value_prime) {
node.prev = undefined;
node.next = undefined;
int_prime.put(node);
}
} else {
// empty queue
return;
}
}
}
This example shows an interesting behavior of queues. The function int_to_test.get() returns a pointer ?*Node, which is not deallocated by the get.
So, you can reuse the it for sending back the result of the test within another queue (is_prime), by taking care to set .prev and .next to undefined.
Finally, the classical .join() waits for all threads to end.
for (pool) |thread| {
thread.join();
}
Previously, I presented an arena thread-safe allocator. But this implementation does not concurrent allocations, they are all
performed in the main thread.
prime_manual.zig: Github
Standard Library
The type std.Thread.Pool from the stdlib maintains a pool of threads. But instead of
putting integer to a queue, we spawn tasks (calls to functions) queued in a RunQueue.
const Pool = std.Thread.Pool;
var thread_pool: Pool = undefined;
try thread_pool.init(Pool.Options{
.allocator = arena, // this is an arena allocator from `std.heap.ArenaAllocator`
.n_jobs = cpu_count, // optional, by default the number of CPUs available
});
defer thread_pool.deinit();
Do not forget thetryin front ofthread_pool.init(), it catches the function’s returned error. In Zig, the returned errors are specified by!-prefixed values, e.g.,pub fn foo() !int.
Instead of spawning a task per integer, I spawn a task for a batch of integer. Actually, testing one integer per task would require more CPU power to spawn the task itself than perform the integer test.
const value_max: u64 = 1000000;
const shard_size: u64 = 1000;
var value: u64 = 0;
while (value < value_max) : (value += shard_size) {
try thread_pool.spawn(isPrimeRoutine, .{ &wait_group, &arena, value, shard_size, &int_prime });
}
So, each task checks in a range [value ; value + shard_size[ all the prime numbers. In contrast with
the previous example, now it requires a thread-safe allocator to create new nodes. Because we allocates the results
nodes simultaneously in each parallel task.
Wait Group
The thread pool does not have a public join member but gets a waitAndWork instead and it requires a
wait group. It may sound odd, but mind to first reset the wait group before using it.
Because it contains an std.Thread.ResetEvent not initialized by default.
const WaitGroup = std.Thread.WaitGroup;
var wait_group: WaitGroup = undefined;
wait_group.reset();
// create thread pool, spawn tasks
thread_pool.waitAndWork(&wait_group);
prime_std.zig: Github
Performances
Standard Library
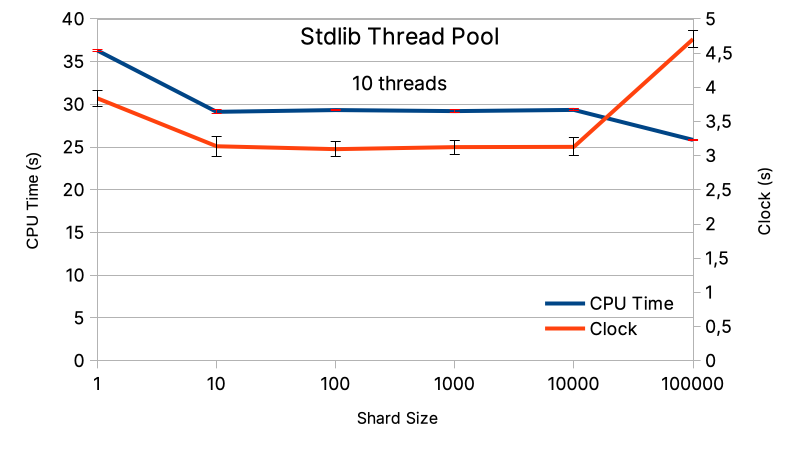
Earlier I spoke about the CPU power balance between spawing a task and running a task. This is visible on the first benchmark (figure below) where for a fixed number of threads (10) the size of the batch varries (from 10 to 100 000). On the left, for baches (or shard) size equal to 10, the task duration increases with respect to the optimum. Also, the CPU time increases because the CPU spends more time to schedule, queue, and unqueue tasks.
The efficiency is also affected by a too large shard size, one can see it for batches of 100 000 integers. The loss of efficiency is due
to the “specialization” of each task. At this batch size, we generate 10 tasks (it fits perfectly to the 10 threads), but their complexity
is heterogeneous. The first task produced evaluates integer in the range [1; 100 000] and the last one in the range [900 001; 1 000 000].
However, for an integer N the algoritms performs all the possible divisions from 2 to N-1, in the worst case scenario. So, the bigger
the integer, the more divisions to perform. Finally, only one thread deals with the most complex task, it ends later, and the join
waits for it to finish its operations.
In opposition to the more balanced shard size runs: 100, 1000, 10 000. They generate smallest tasks with a smoother distribution of complexity between tasks. Consequently, the most complex tasks are not reserved to one thread. For instance at shard size equal to 10 000, and in a simplified model, thread 0 and 9 would run those tasks:
- Thread 0:
[1; 10 000], …,[900 001; 910 000] - …
- Thread 9:
[90 001; 100 000], …,[990 001; 1 000 000]
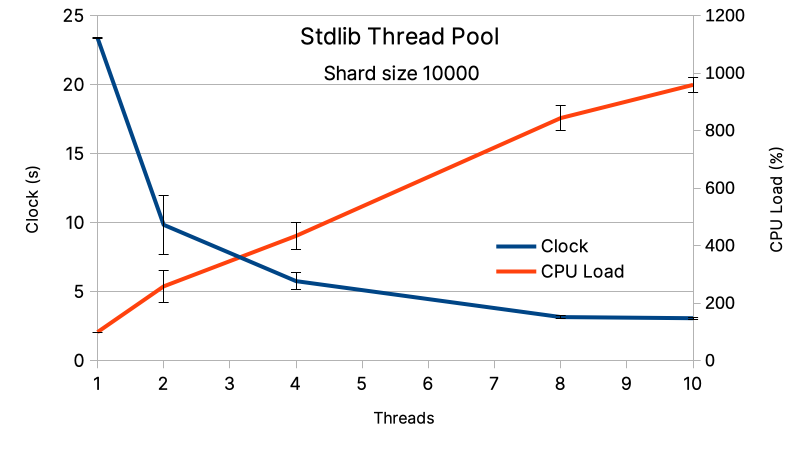
At a fixed shard size of 10 000 integers, the variation of the number of tasks running in parallel has a huge impact (figure below). The performances increases with the number of tasks in parallel (equal to the number of threads running), until they damp for about 8 threads. This sounds compatible with architecture of the M1 10 cores, Apple says 8 cores for “computing” and 2 for “optimization”. However, I noticed a huge variance of the samples (visible in the error bars). For instance, à 2 tasks in parallel if often found my CPU load at about 300%. I cannot explain yet the reason of this high variability.
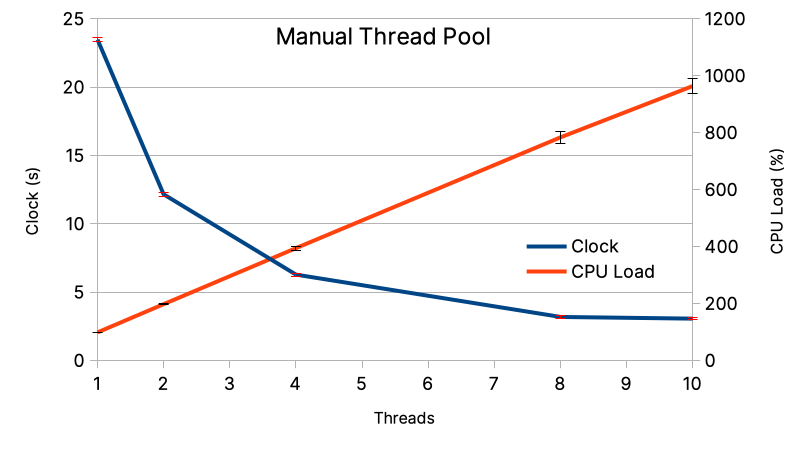
Manual
The benchmark of the manual implementation gives smoother results, and a beautify relation between the number of threads and the CPU load.
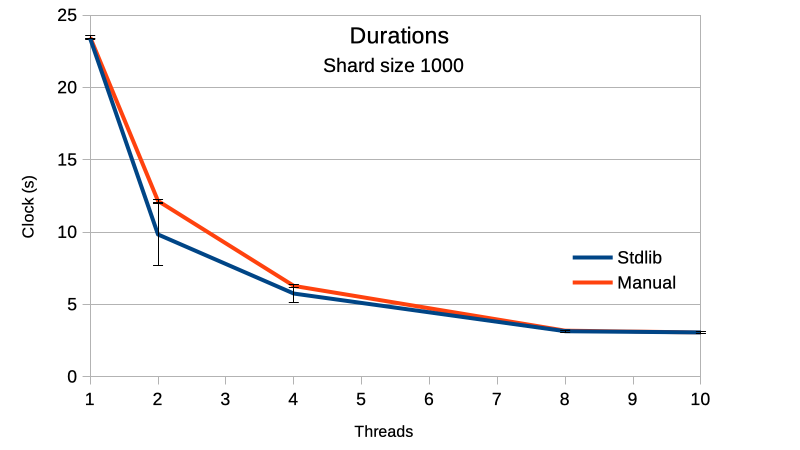
When compared to the stdlib implementation the results are close one to another, the program duration are within the same error
range.
Conclusion
I cannot conclude in favor of the stdlib or not, and it is similar for the manual implementation. I found the stdlib implementation easy to setup and versatile, in opposition to my custom made solution. If you need to control exactly the number of tasks running and the CPU load, I would recommend a manual implementation. If this is not a need the stdlib thread pool is convinient.